Pythonでフォントファイル(ttc)からMicroPython用(LS027B4DH01)のフォントデータを作成する
2020/08/15 categories:Python| tags:Python|MicroPython|LS027B4DH01|NumPy|Font|
MicroPythonを入れたESP32でLS027B4DH01に文字を表示するために必要なフォントデータをPCでPythonを使って作成しました。
フォントファイルからnumpy配列を作成
フォントファイルからMicroPythonの表示用データを作成するために、まずはPillowで1文字だけの画像を作成しました。使用するフォントはMSゴシックです。Image.new()の最初の引数を’1’とすることでモノクロ画像になります。その画像をnumpy.array()に渡すことでbooleanの配列が得られます。例として「B」の文字を変換してみます。
font_path = 'C:\\Windows\\Fonts\\msgothic.ttc'
character = 'B'
font = ImageFont.truetype(font_path, font_size)
draw = ImageDraw.Draw( Image.new('1', (1, 1), (0)) )
text_size = draw.textsize(character, font)
image = Image.new('1', text_size, (0))
draw = ImageDraw.Draw(image)
draw.text( (0, 0), character, fill=font_color, font=font )
array = np.array(image)出力結果

boolean配列をintに変換
booleanのnumpy配列をnumpy.astype(numpy.uint8)に渡すことで0と1のintの配列に変換できます。ここでは符号なし整数uint8としました。
array = array.astype(np.uint8)
出力結果

intの配列を0と1の文字列に変換
1行分のデータを0と1が連続する文字列に変換して、数値データを作成しやすい形式にします。
array = [ ‘’.join([ str(j) for j in i ]) for i in array ]
出力結果

文字列を逆の順番にする
MicroPythonのSPI通信でLS027B4DH01にデータを送る場合、小さいビットから送る必要があったので文字列を反転します。
array = [ i[::-1] for i in array ]
出力結果

文字列を8文字ごとにリストに分ける
16進表記の文字列に変換しやすいように、文字列を8文字ごとのリストとして分割します。
array = [
[
s[ cnt*8 : cnt*8+8 ] for cnt in range( int(len(s)/8) )
] for s in array
]
リストを逆の順にする
文字列を逆にするときと同様に、MicroPythonのSPI通信でLS027B4DH01にデータを送る場合、小さいバイトから送る必要があったので8文字ごとのリストを反転して逆の順番にします。
array = [ ls[::-1] for ls in array ]

8文字ごとのリストを要素ごとに16進数表記の文字列に変換する
MicroPython用のbytearrayを作成するために、文字列を16進数表記に変換します。
array = [
[
'\\x' + format( ~int(data, 2) & 0xFF, '02x' ) for data in ls
] for ls in array
]
分割されている要素を行単位で結合する
ここまでで文字列の表記についての変換が終わったので、最終的な文字列に変換するために行ごとの要素を結合して1つの文字列にします。
array = [ ‘’.join(ls) for ls in array ]
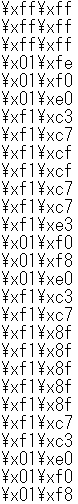
各行を結合して1つの文字列にする
行ごとの文字列をすべて結合して一つの文字列にします。この文字列の前後に辞書のキーとなる文字列「’B’:」とbytearrayの文字列「bytearray(b”)」を追加します。
text = "'" + character + "' : bytearray(b'" + ''.join(array) + "')"
'B' : bytearray(b'\xff\xff\xff\xff\xff\xff\x01\xfe\x01\xf0\x01\xe0\xf1\xc3\xf1\xc7\xf1\xcf\xf1\xcf\xf1\xc7\xf1\xc7\xf1\xe3\x01\xf0\x01\xf8\x01\xe0\xf1\xc3\xf1\xc7\xf1\x8f\xf1\x8f\xf1\x8f\xf1\x8f\xf1\x8f\xf1\xc7\xf1\xc3\x01\xe0\x01\xf0\x01\xf8')最終的なフォントデータ
最終的なデータはfont_16という辞書が書かれたfont_16.pyというファイルにしました。フォントデータに含まれる文字は0~9、a~z、A~Zでファイルサイズは16KBです。内容は下記のような感じです。
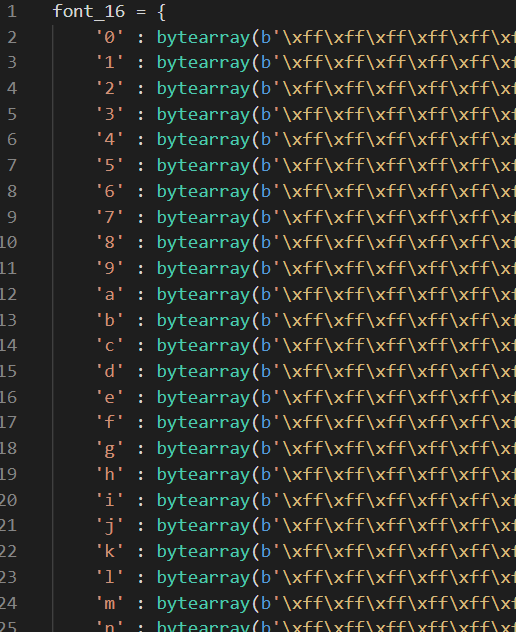
ソースコード
from PIL import Image, ImageDraw, ImageFont
import numpy as np
def character_to_text(font_path, character, font_size, font_color):
font = ImageFont.truetype(font_path, font_size)
draw = ImageDraw.Draw( Image.new('1', (1, 1), (0)) )
text_size = draw.textsize(character, font)
image = Image.new('1', text_size, (0))
draw = ImageDraw.Draw(image)
draw.text( (0, 0), character, fill=font_color, font=font )
# image to numpy array (boolean)
array = np.array(image)
# boolean array to int array
array = array.astype(np.uint8)
# int array to str array
array = [ ''.join([ str(j) for j in i ]) for i in array ]
# str reverse
array = [ i[::-1] for i in array ]
# split 8 bit
array = [
[
s[ cnt*8 : cnt*8+8 ] for cnt in range( int(len(s)/8) )
] for s in array
]
# reverse byte
array = [ ls[::-1] for ls in array ]
# binary string to hex string
array = [
[
'\\x' + format( ~int(data, 2) & 0xFF, '02x' ) for data in ls
] for ls in array
]
# string list join
array = [ ''.join(ls) for ls in array ]
# string list join
text = "'" + character + "' : bytearray(b'" + ''.join(array) + "')"
return text
def main():
font_path = 'C:\\Windows\\Fonts\\msgothic.ttc'
characters = [str(i) for i in range(10)]
characters += [chr(i) for i in range(97, 97+26)]
characters += [chr(i) for i in range(65, 65+26)]
text = 'font_16 = {' + '\n'
for character in characters:
text += ' '
text += character_to_text(font_path, character, 32, 'white')
text += ',\n'
text = text[0:-2] + '\n' + '}' + '\n'
with open('font_16.py', mode='w') as f:
f.write(text)
if __name__ == "__main__":
main()