PythonとPopplerで大量のPDFを用紙サイズごとに結合
2020/02/29 categories:Python| tags:Python|PyQt5|Poppler|
PythonとPopplerを使ってPDFを用紙サイズごとに結合するプログラムを作成しました。GUIは毎度おなじみのPyQt5です。
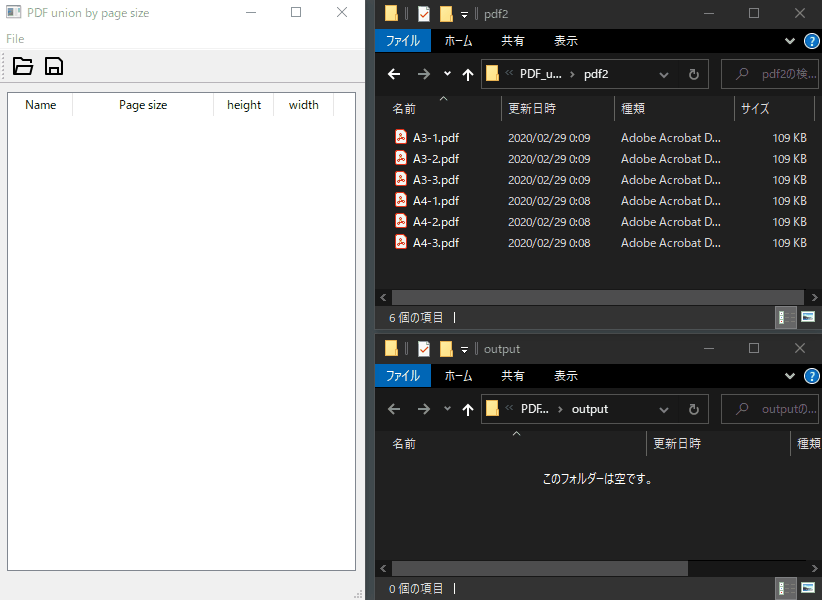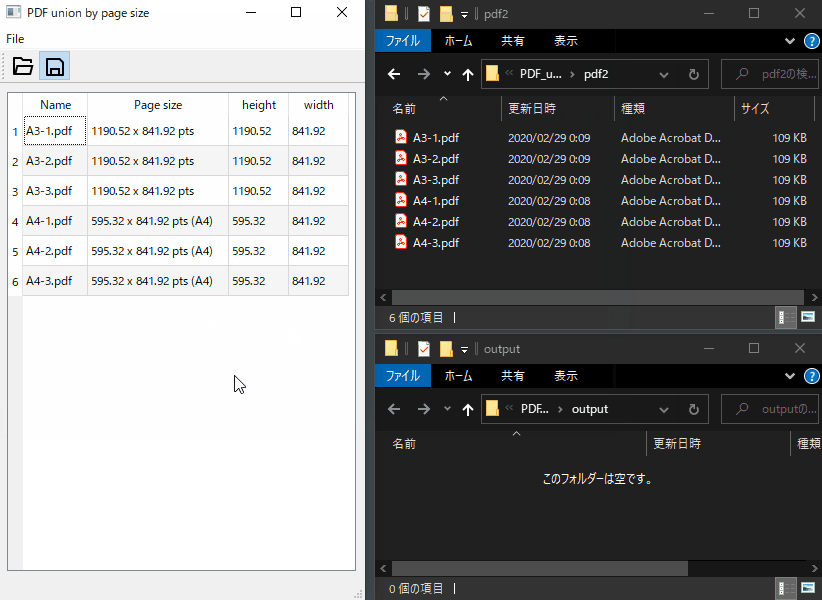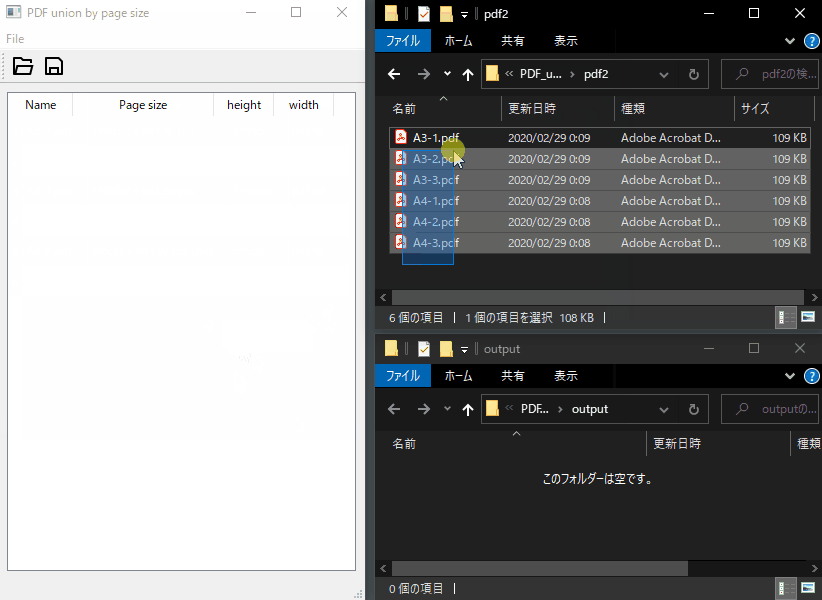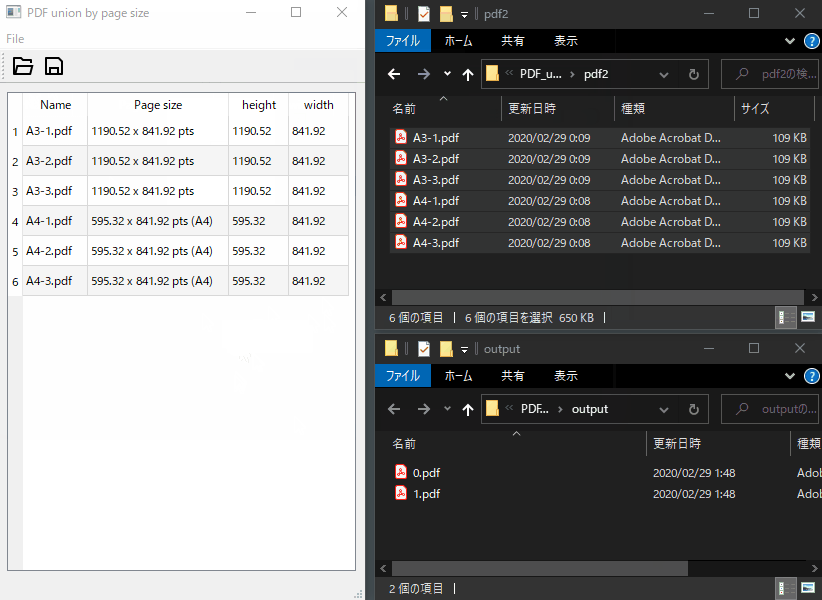
subprocessでPopplerの呼び出し
Pythonからsubprocessモジュールを使ってpoppler-0.68.0に含まれるpdfunite.exeとpdfinfo.exeを呼び出してPDFの処理をしています。subprocessで実行するメソッドは下記の通りです。
def subprocess_popen(self, cmd):
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
startupinfo.wShowWindow = subprocess.SW_HIDE
proc = subprocess.Popen(cmd, encoding='cp932', stdout=subprocess.PIPE, stderr=subprocess.PIPE, startupinfo=startupinfo)
stdout, stderr = proc.communicate(timeout=50)
return stdout, stderrsubprocessではstartupinfoを指定してウィンドウを表示しないようにしています。今回使ったPCはWindows 10なので標準出力を文字列で受け取るためにencoding=’cp932’で文字コードを指定しています。
PDFのpage sizeを取得
pdfinfo.exeにPDFファイルを渡すと下記のように出力されます。
PS *:\*****\poppler-0.68.0\bin> .\pdfinfo A4.pdf
Title: Book1
Author: ********
Producer: Microsoft: Print To PDF
CreationDate: 02/29/20 00:08:52 東京 (標準時)
ModDate: 02/29/20 00:08:52 東京 (標準時)
Tagged: no
UserProperties: no
Suspects: no
Form: none
JavaScript: no
Pages: 1
Encrypted: no
Page size: 595.32 x 841.92 pts (A4)
Page rot: 0
File size: 110952 bytes
Optimized: no
PDF version: 1.7この出力結果からPage sizeの行を取得します。まずは下記のようにpdfinfoを実行します。
def pdfinfo(self, pdf_path):
stdout, stderr = self.subprocess_popen( ['poppler-0.68.0/bin/pdfinfo.exe', pdf_path] )
return stdout, stderr読み込んだPDFの情報をPyQt5のQTableViewに表示させるため、下記のように、pdfのパスを受け取ったらpdfの情報をpdfinfoで読み取り、その情報をアイテムに追加するという処理をしました。
def pdfs_to_items(self, pdf_paths):
self.model.removeRows(0, self.model.rowCount())
paths = [ Path(pdf_path) for pdf_path in pdf_paths ]
self.model.insertRows(0, len(paths))
for row, path in enumerate(paths):
item = self.model.index( row, 0, QtCore.QModelIndex() ).internalPointer()
stdout, stderr = self.pdfinfo(str(path))
if not stderr == '':
continue
lines = [ line.split(':') for line in stdout.splitlines() ]
d = { line[0].strip():line[1].strip() for line in lines }
s = d['Page size'].split()
d2 = { 'Name':str(path.name), 'Path':str(path), 'height':s[0], 'width':s[2] }
d.update(d2)
item.set_dict(d)PDFをpage sizeごとに結合
結合にはpdfunite.exeを使いました。下記のように実行しています。
def pdfunite(self, pdfs, filename):
cmd = ['poppler-0.68.0/bin/pdfunite.exe']
cmd.extend(pdfs)
cmd.append(filename)
stdout, stderr = self.subprocess_popen(cmd)
return stdout, stderrPDFをpage sizeごとに保存する処理は下記の通りです。
def filesave(self):
savefolder = 'output/'
items = self.model.root_item.children()
sizes = set([item.data('Page size') for item in items])
pdfs = { size:[] for size in sizes }
for item in items:
pdfs[item.data('Page size')].append(item.data('Path'))
for n, key in enumerate(pdfs):
self.pdfunite( pdfs[key], savefolder + str(n) + '.pdf' )モデルからアイテムを取得して、アイテムからPDFのパスやpage sizeなどを取得して、page sizeごとにpdfuniteを実行して結合していくという処理です。
図面を扱うときなどに大量のPDFを処理することがあります。その時に、用紙サイズごとに分けてほしいとか図面リストに用紙サイズを入力してほしいなどといった要望があったりします。また、たくさんのPDFを印刷するときなどにも一旦用紙サイズごとに結合してから印刷することで作業効率を上げることが出来ます。そのために今回のようなプログラムを作ってみました。
使用頻度はそんなに多くないかもしれませんが、あると地味に便利なプログラムかなと思います。