Pythonでダウンローダーを作ってみた
2021/10/03 categories:TOOL| tags:Python|pyqt5|BeautifulSoup|urllib|
Pythonでホームページ上の画像を保存するダウンローダーを作成してみました。
処理内容
今回作ったソフトは、ページ内のimgタグからソースへのリンクを取得して、それらのデータをダウンロードする処理をします。処理するページを簡単に指定できるように、クリップボードの変化を監視して、クリップボード内のテキストがURLである場合に処理を実行するようにしました。
クリップボードの監視
QtWidgets.QApplication.clipboardのdataChangedのシグナルがエミットされたら、クリップボードのデータをチェックするような処理にしました。
self.clipboard = QtWidgets.QApplication.clipboard()
self.clipboard.dataChanged.connect(self.clipboard_cnaged)
def clipboard_cnaged(self):
text = self.clipboard.text()
if not text[:4] == 'http':
returnページ内のimgを取得
BeautifulSoupを使ってimgタグを取得し、imgタグのsrcを取得することで画像のソースのリンクを取得します。
parse = urllib.parse.urlparse(text)
url_base = parse.scheme + '://' + parse.netloc + '/'
res = requests.get(text)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
title = str( soup.find_all('h2')[0].get_text() )
if not Path(title).exists():
Path(title).mkdir()
article = soup.find_all('article', {'class': 'content'})[0]
images = article.find_all('img')
for image in images:
image_link = image['src']
if image_link[0] == '/':
image_link = url_base + image_link
self.model.appendRow([ QtGui.QStandardItem(title), QtGui.QStandardItem(image_link) ])データのダウンロード
データのダウンロードには時間がかかるので、メインウィンドウでダウンロードを処理するとウィンドウの描画が止まってしまい、ソフトがフリーズしているように見えてしまいます。そこで、QThreadでダウンロードを実行することでウィンドウの描画が止まらないようにしました。
class Downloader(QtCore.QThread):
def __init__(self, parent):
super(Downloader, self).__init__(parent)
def run(self):
model = self.parent().model
while model.rowCount() > 0:
try:
title = model.item(0, 0).text()
image_link = model.item(0, 1).text()
save_path = title + '/' + Path(image_link).name
url_data = requests.get(image_link).content
with open(save_path ,mode='wb') as f:
f.write(url_data)
except Exception as e:
print(e)
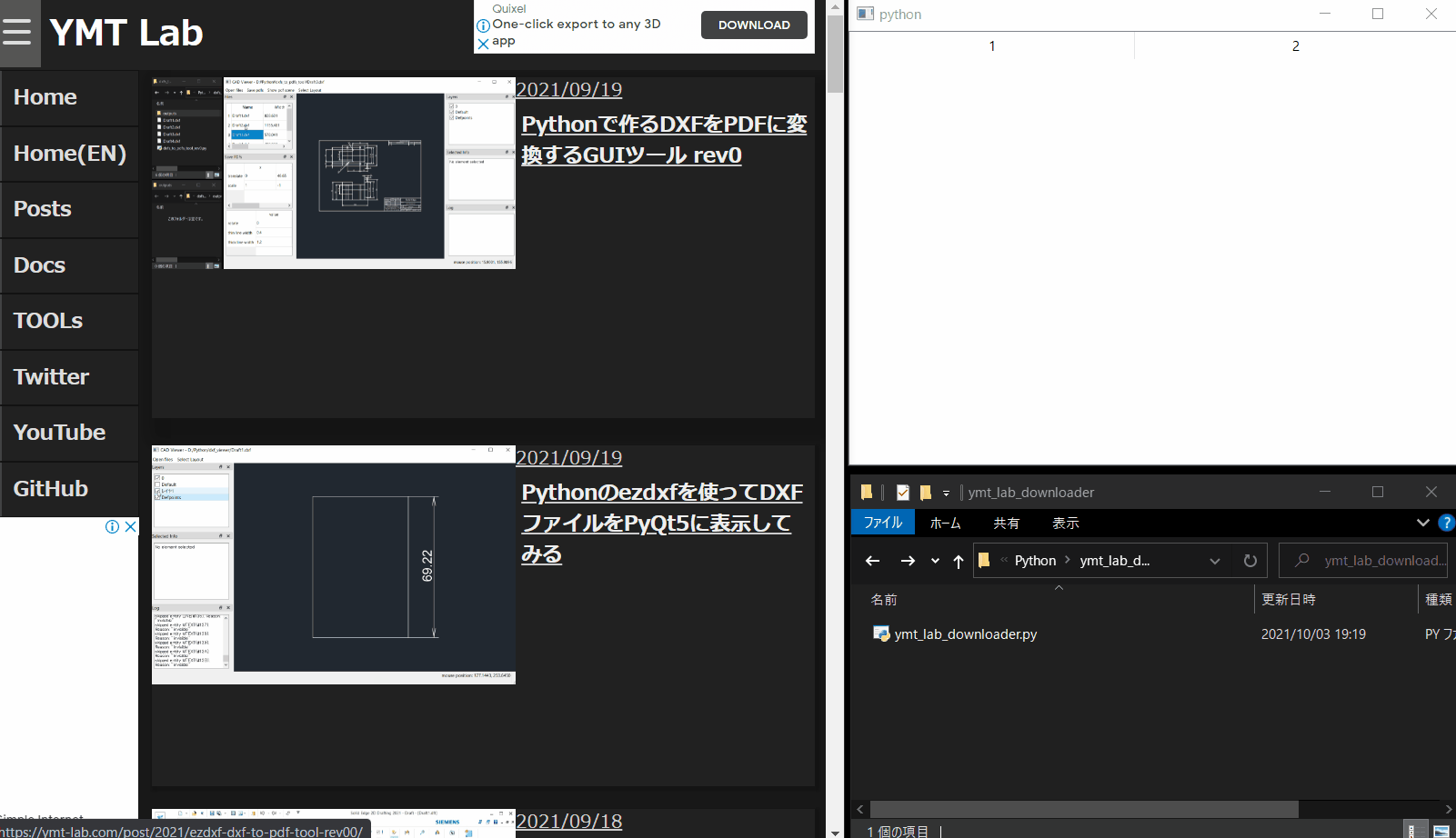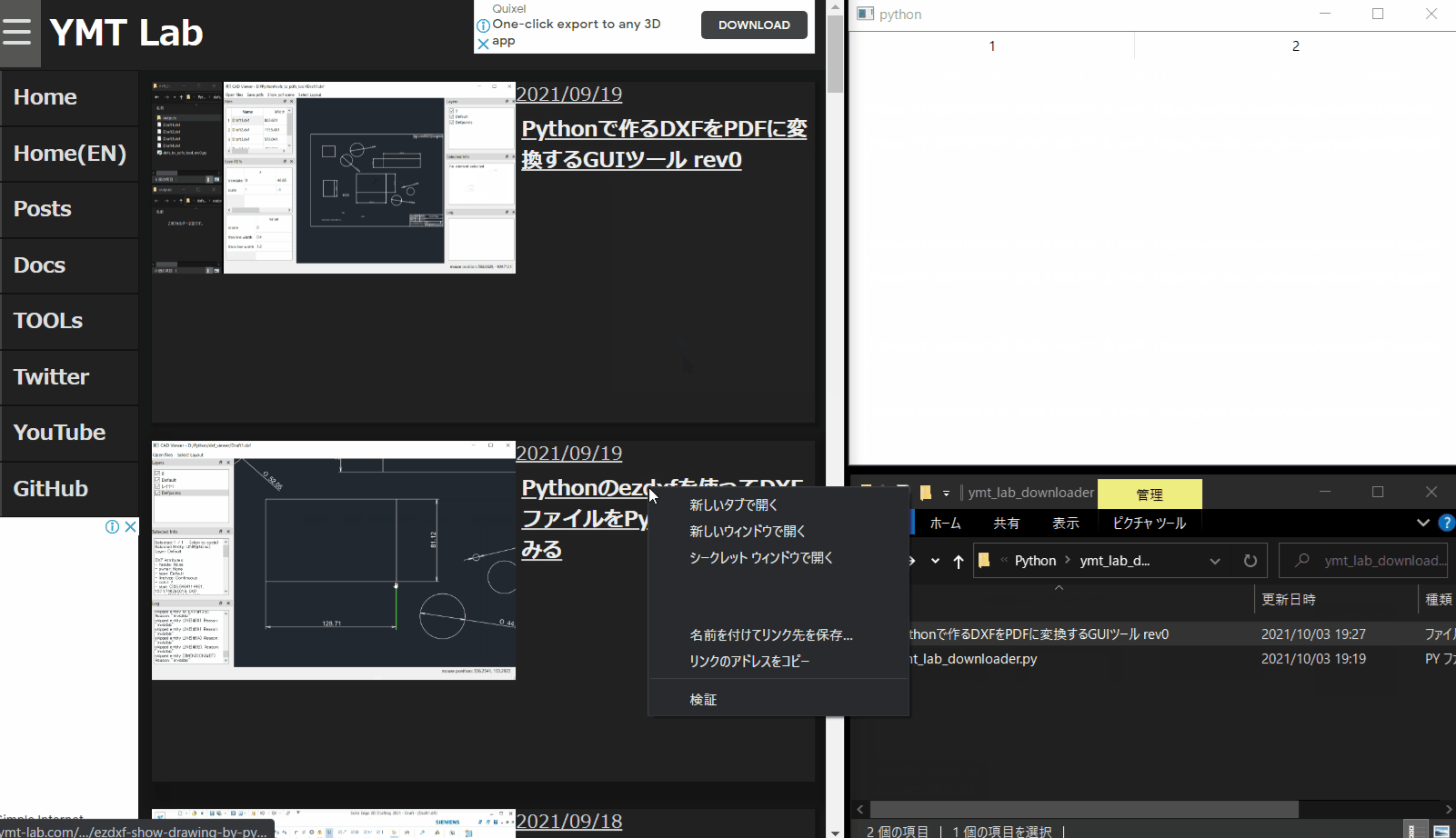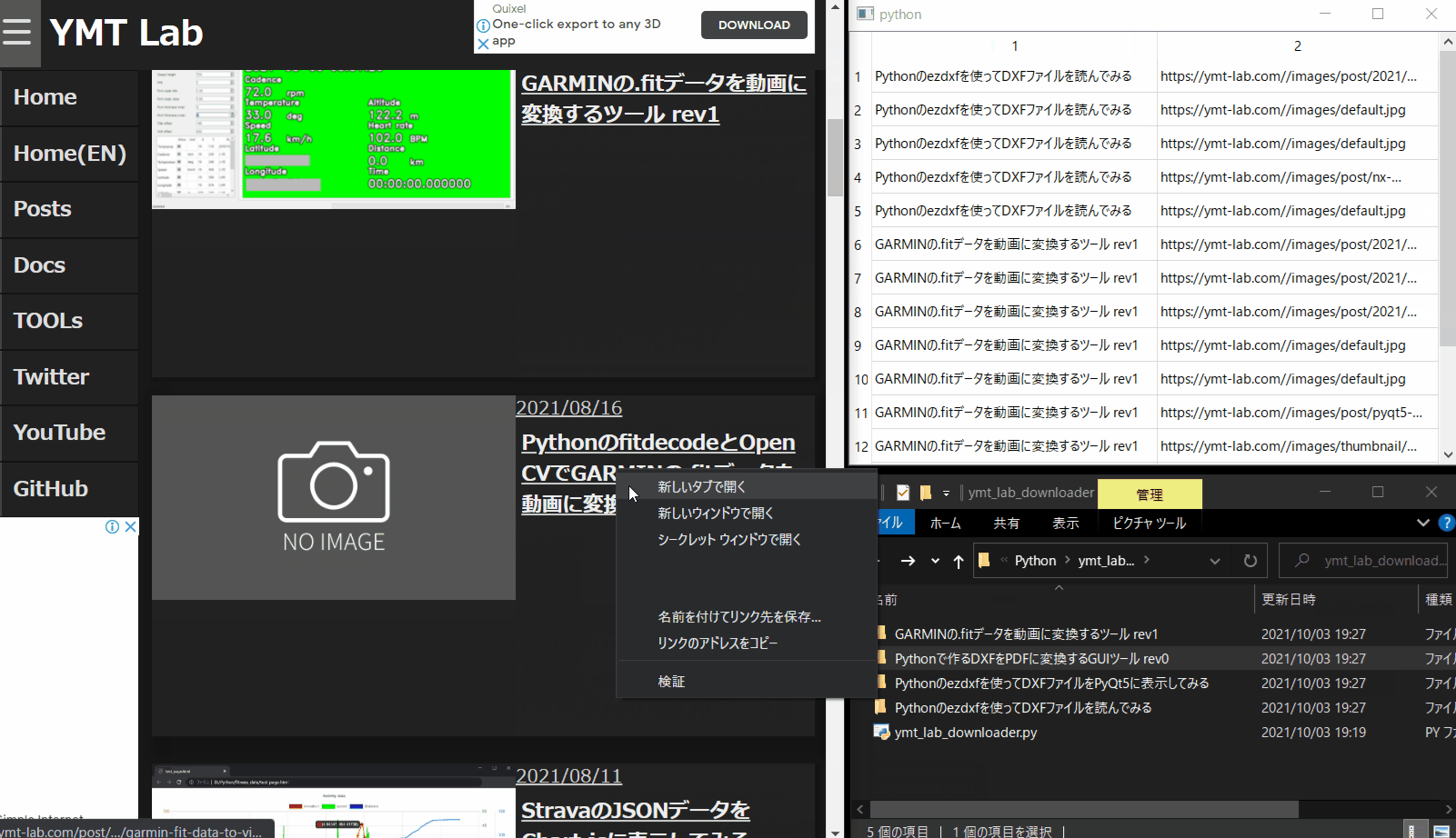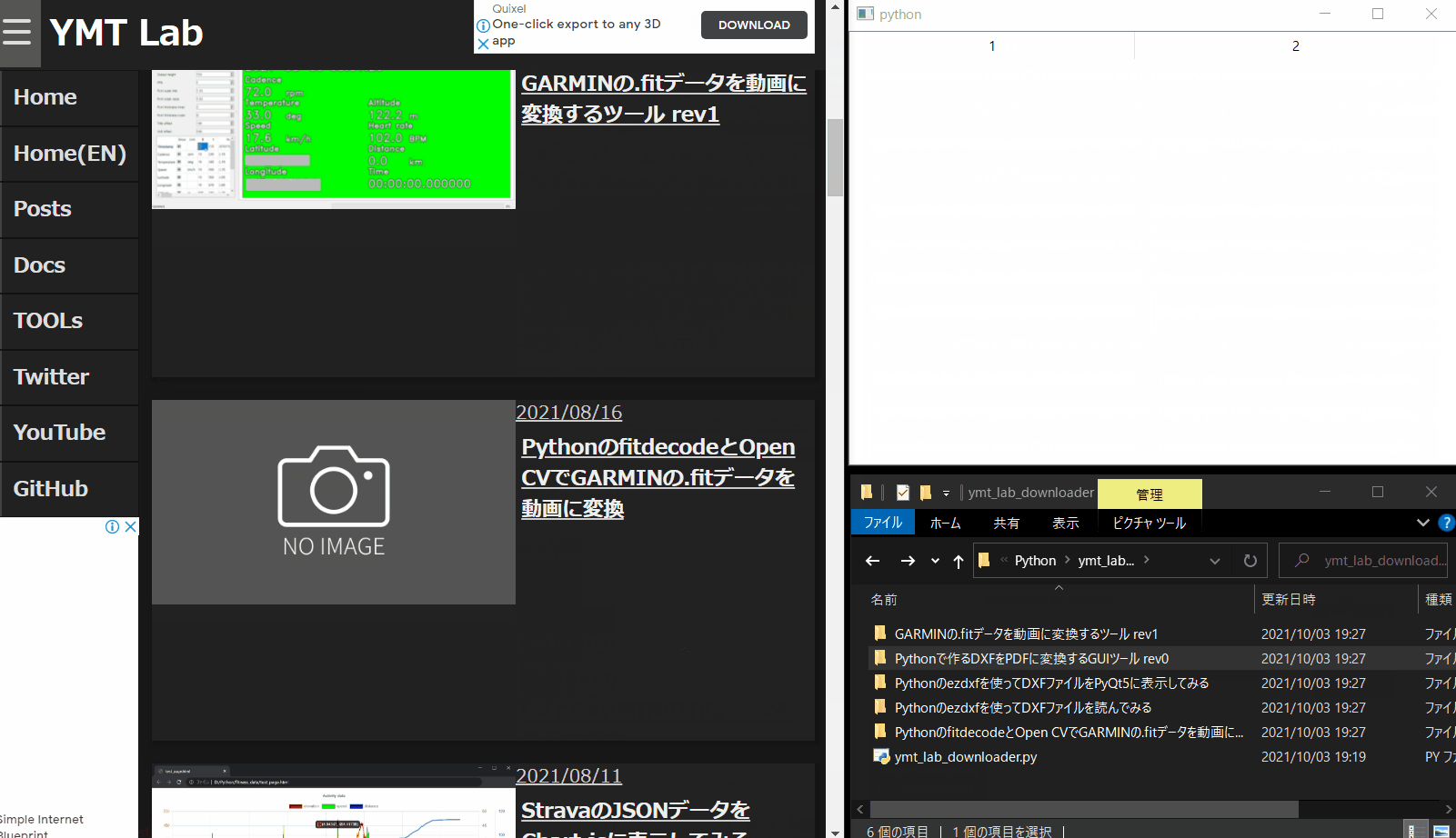
model.removeRow(0)使用イメージ
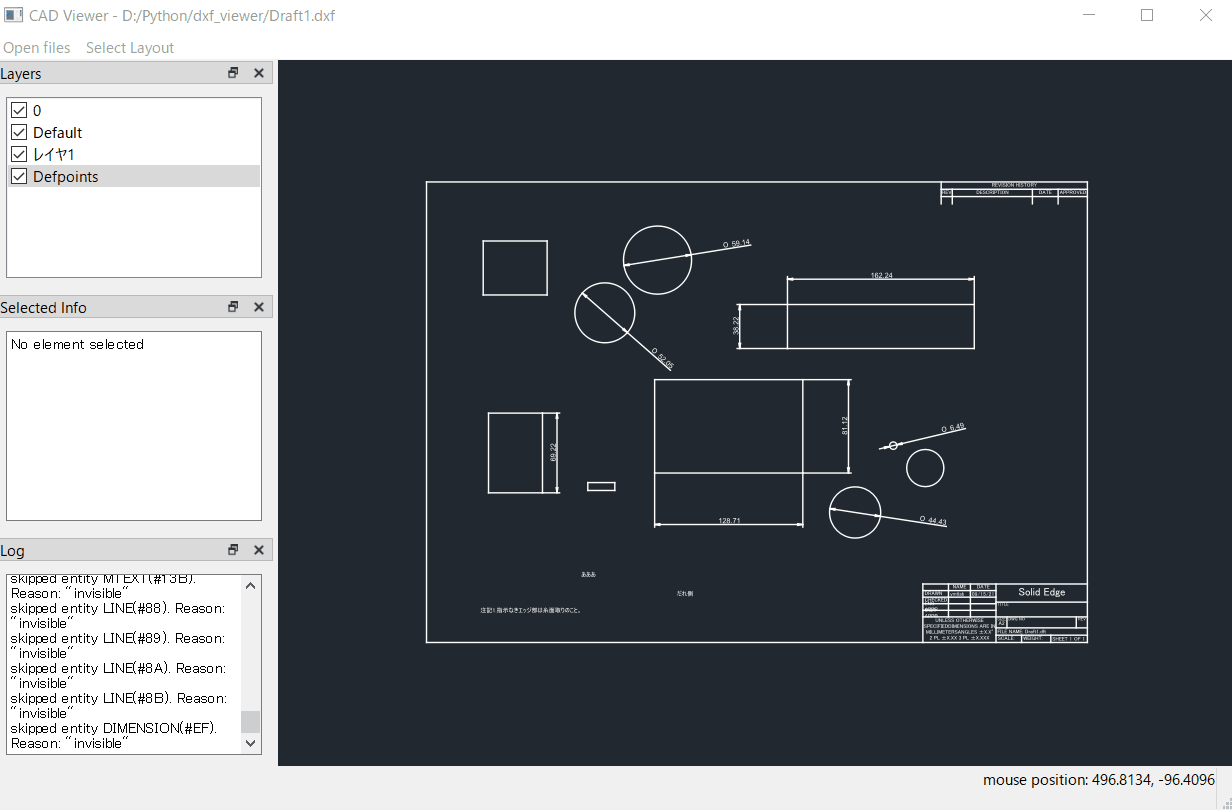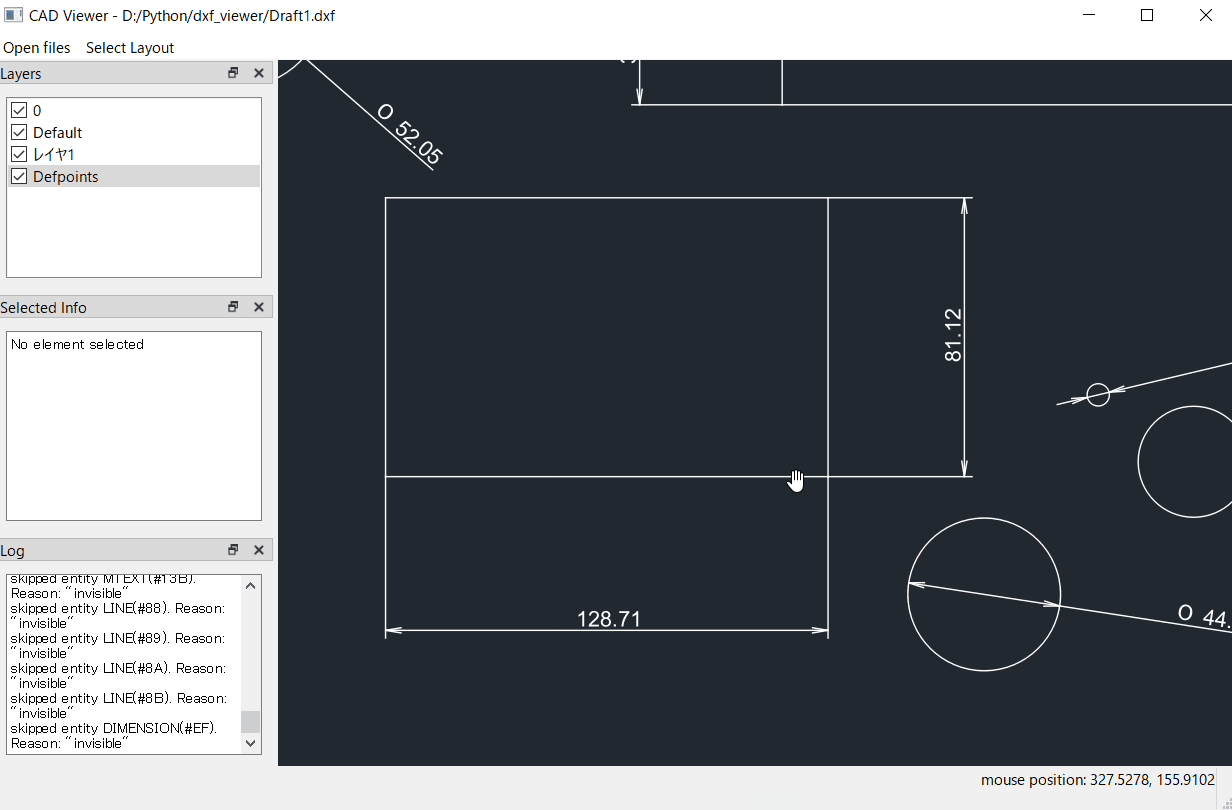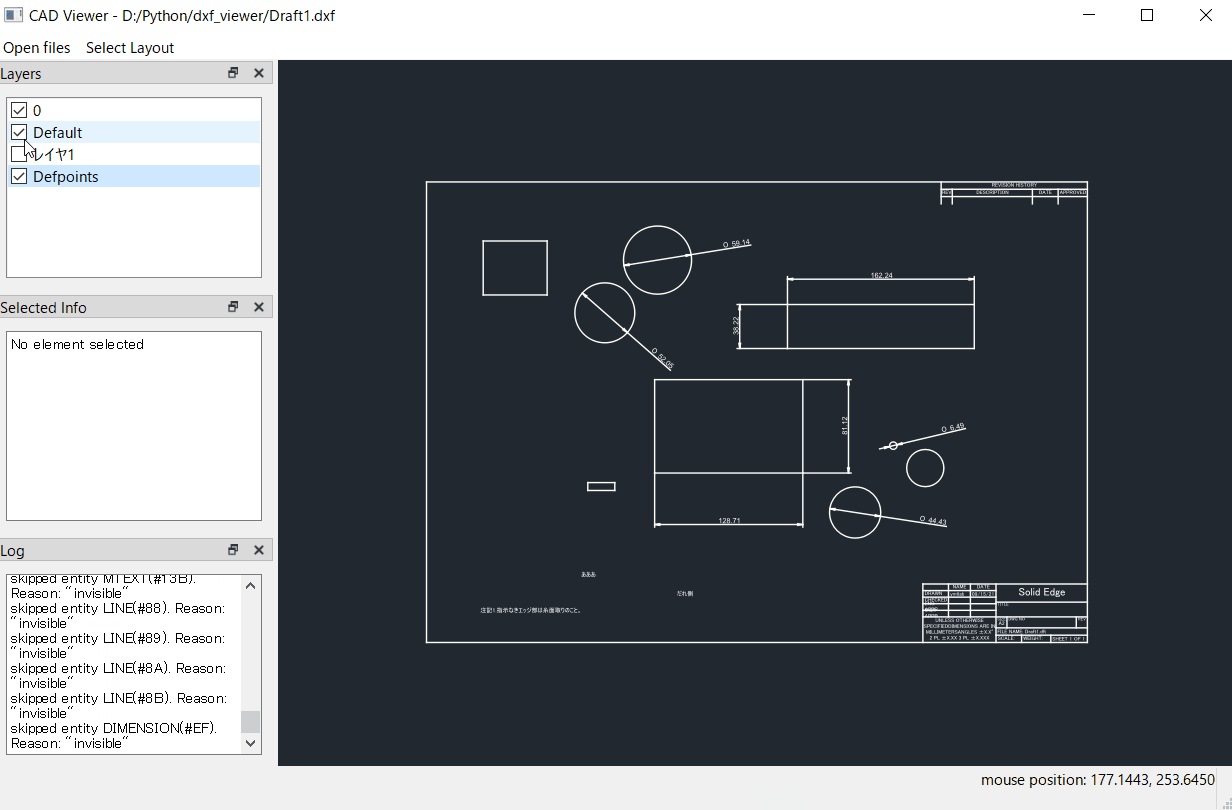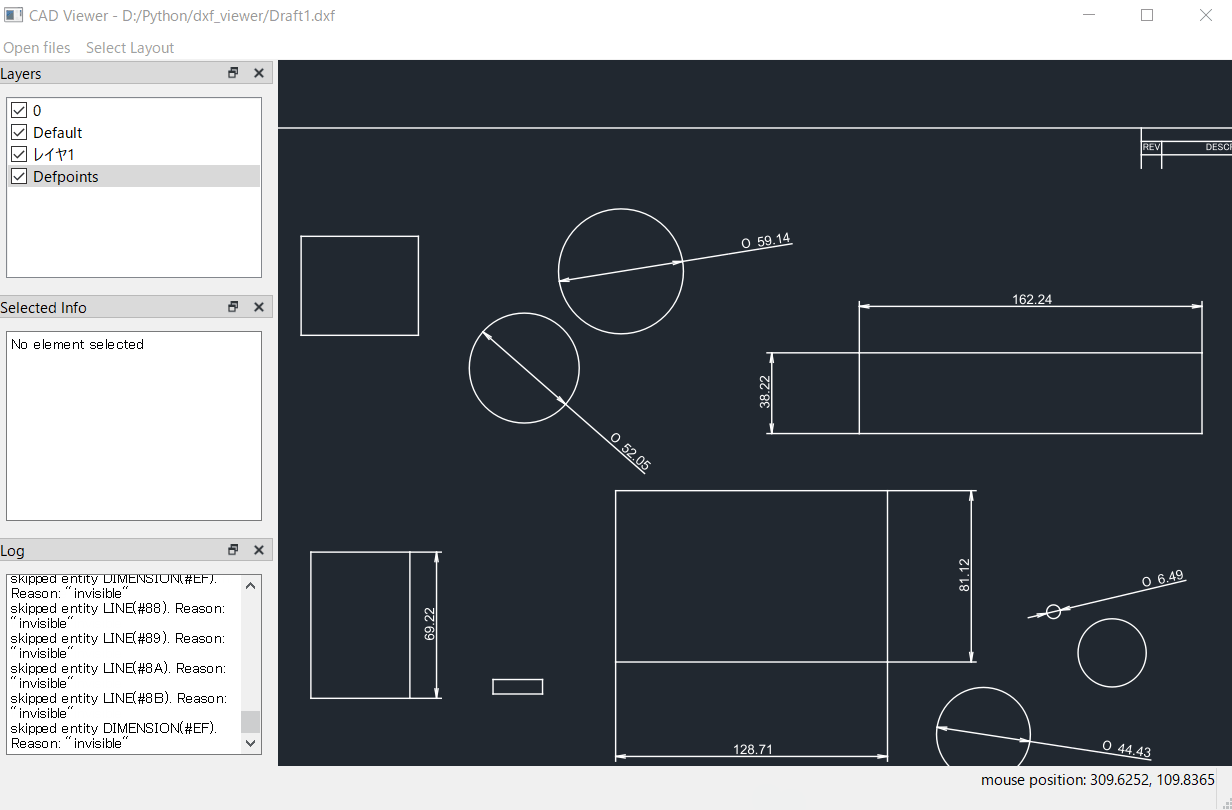
自分のページのリンクをコピーして、ページ内の画像を取得するイメージです。
ソースコード
import requests
import sys
import urllib
from bs4 import BeautifulSoup
from pathlib import Path
from PyQt5 import QtWidgets, QtCore, QtGui
class Downloader(QtCore.QThread):
def __init__(self, parent):
super(Downloader, self).__init__(parent)
def run(self):
model = self.parent().model
while model.rowCount() > 0:
try:
title = model.item(0, 0).text()
image_link = model.item(0, 1).text()
save_path = title + '/' + Path(image_link).name
url_data = requests.get(image_link).content
with open(save_path ,mode='wb') as f:
f.write(url_data)
except Exception as e:
print(e)
model.removeRow(0)
class MainWindow(QtWidgets.QMainWindow):
def __init__(self, parent=None, flags=QtCore.Qt.WindowFlags()):
super().__init__(parent=parent, flags=flags)
self.model = QtGui.QStandardItemModel()
self.table = QtWidgets.QTableView(self)
self.table.setModel(self.model)
self.table.horizontalHeader().setStretchLastSection(True)
self.downloader = Downloader(self)
self.setCentralWidget(self.table)
self.clipboard = QtWidgets.QApplication.clipboard()
self.clipboard.dataChanged.connect(self.clipboard_cnaged)
def clipboard_cnaged(self):
text = self.clipboard.text()
if not text[:4] == 'http':
return
parse = urllib.parse.urlparse(text)
url_base = parse.scheme + '://' + parse.netloc + '/'
res = requests.get(text)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
title = str( soup.find_all('h2')[0].get_text() )
if not Path(title).exists():
Path(title).mkdir()
article = soup.find_all('article', {'class': 'content'})[0]
images = article.find_all('img')
for image in images:
image_link = image['src']
if image_link[0] == '/':
image_link = url_base + image_link
self.model.appendRow([ QtGui.QStandardItem(title), QtGui.QStandardItem(image_link) ])
self.downloader.start()
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
window = MainWindow()
window.show()
app.exec_()